深入浅出 SSD(二):SSD 核心技术:FTL
本文介绍 SSD 的核心技术 FTL(闪存转换层)
一、FTL 综述
FTL(Flash Translation Layer,闪存转换层),是 SSD 固件的核心组成,完成主机(Host)逻辑地址空间到闪存(Flash)物理地址空间的翻译(Translation),或映射(Mapping)。SSD 使用的存储介质一般是 NAND Flash
闪存块的有以下重要特性:
- 闪存块需要先擦除才能写入,不能覆盖写,当写入新数据时,不能在老地方更改,因为闪存不允许在一个闪存页上重复写入,一次擦除只能写一次。因此 Firmware 固件需要维护一张逻辑地址到物理地址的映射表。当闪存空间不够时,FTL 就需要做垃圾回收,将若干个闪存块中的有效数据搬出,写到某个新的闪存块上,然后把之前的闪存块删除,得到新的闪存块。
- 闪存块都是有一定寿命的,可以用 PE(Program/EraseCount)数衡量,通过 Wear Leveling 让数据均摊到每个闪存块上,保证 SSD 的最大数据写入量。
- 每个闪存块读的数量是有限的,读的太多会造成读干扰(Read Disturb)问题,FTL 需要处理读干扰问题,当某个闪存块读次数快到一定阈值的时候,FTL 需要将其从闪存块中移走,避免数据出错。
- 闪存的数据保持问题(Data Retention)问题。(电荷流失)
- 闪存的坏块。
- 对 MLC 和 TLC 来说,存在 Lower page corruption 问题。
- MLC 或 TLC 的读写速度都不如 SLC,但它们都可以配成 SLC 模式来使用。
FTL 分为 Host Based(基于主机)和 Device Based (基于设备),目前主流 SSD 都是基于设备。
二、映射管理
1. 映射种类
- 基于块的映射
- 对小尺寸数据写入不友好,对大尺寸数据写入友好
- U 盘一般采用块映射
- 基于页的映射
- 需要更大的映射表
- 随机写性能更好
- SSD 一般采用页映射
- 混合映射(Hybrid Mapping)
2. 映射基本原理
用户通过 LBA(Login Block Address,逻辑块地址)访问 SSD,用户访问 SSD 的基本单元叫逻辑页,SSD 主控按照闪存页为基本单位读写 SSD,闪存页也叫物理页。
映射表
3. HMB
映射表可以放在 DRAM、SRAM 和闪存中,也可以放到主机的内存中
HMB(Host Memory Buffer,主机高速缓冲存储器),主机在内存中专门划出一部分空间给 SSD 用,SSD 可以把它当成自己的 DRAM 使用。在性能上,它应该介于带 DRAM 和不带 DRAM 之间。带 DRAM 的 SSD,性能好,但是能耗高,成本高;不带 DRAM 的 SSD 与其相反,需要访问两次闪存才能得到数据。
4. 映射表刷新
映射表在 SSD 掉电前需要将其写入到闪存中。下次上电初始化时,需要把它从闪存中部分或全部加载到 SSD 的缓存(DRAM或者SRAM)中。为防止异常掉电导致这些新的映射关系丢失,SSD 的固件不仅仅只在正常掉电前把这些映射关系刷新到闪存中去,而是在 SSD 运行过程中按照一定策略把映射表写进闪存,这样可以防止异常掉电带来的映射关系的丢失。
触发映射表的写入时机:
- 新产生的映射关系累积到一定的阈值
- 用户写入的数据量达到一定的阈值
- 闪存写完闪存块的数量达到一定的阈值
- 其他
写入策略一般有:
- 全部更新
- 增量更新
三、垃圾回收
1. 垃圾回收原理
2. 写放大
由于 GC 的存在,就有一个问题,用户要写入一定的数据,SSD 为了腾出空间写这些数据,需要额外的做一些数据的搬移,也就是额外的写,最后往往导致 SSD 往闪存中写人的数据量比实际用户写入 SSD 的数据量多。因此,SSD 中有个重要参数,就是 写放大(WA, Write Amplification):
$$写放大=\cfrac{写入闪存的数据量}{用户写的数据量}$$
空盘的写放大一般为 1,写放大越大,意味着额外写入闪存的数据越多,一方面磨损闪存,减少 SSD 寿命,另一方面,写人这些额外数据会占用底层闪存带宽,影响 SSD 性能。因此,SSD 设计的一个目标是让 WA 尽量小。减小写放大,可以使用前面提到的压缩办法(主控决定),顺序写也可以减小写放大(垃圾集中,但顺序写可遇不可求,取决于用户 Workload),还有就是增大OP(这个可控)。
OP 定义:$OP比例=(闪存空间-用户空间)/用户空间$,增大 OP 能够减小写放大。
总结一下: WA 越小越好,因为越小意味着对闪存的损耗越小,可以延长闪存使用寿命,从而支持更多的用户数据写入量;OP 越大越好,OP 越大,意味着写放大越小,也意味着 SSD 写性能越好。
影响写放大的因素:
- OP
- 用户写入数据的 Pattern(顺序写入还是随机写入)
- GC 策略
- 磨损均衡
- 读干扰和数据保存处理
- 主控:是否对数据有压缩
- Trim
3. 垃圾回收实现
垃圾回收可以简单分为三步:
- 挑选源闪存块
- 从源闪存块中找到有效数据
- 把有效数据写入到目标闪存块
1. 挑选源闪存块
- 挑选有效数据最小的块
- 固件需要记录和维护每个闪存块的有效数据量
- 这种 BPA 算法叫做 Greedy 算法,是大多数 SSD 使用的算法
- 有的 BPA 还需要考虑到擦写次数
2. 从源闪存块中找到有效数据
最好的策略当然是只读出块中的有效数据
- 固件在更新和维护闪存块中的有效数据量时,同时维护一张映射表,标识物理页的有效性
- 当然这种策略也有一个问题,当 SSD 很大时,一个闪存块有上千个闪存页,一个闪存页有上千个逻辑页,因此每个闪存块需要的映射表就会非常大,对于没有 DRAM 的 SSD,没有那么多的 SRAM 空间存储映射表,只能加载部分映射表,因此还要实现映射表的换入换出,实现起来较为困难
也可以选择把所有数据都读出来,这样就要判断哪些数据是有效的
- SSD 在将用户数据写入闪存时,会额外打包一些数据,叫元数据(Meta data),它记录该用户数据的一些信息,例如该数据对应的逻辑地址、数据长度、时间戳等
- 然后 GC 的时候,FW 读出该数据,得到该数据的逻辑块地址,然后查找映射表,获得物理地址,如果该地址和该数据在闪存中的地址一致,说明数据是有效的,否则无效
- 该方法显而易见太过繁琐
还有一个折中的办法,除了维护一张 L2P(Logical to Physical) 的表,还维护一张 P2L(Physical to Logical) 的表
该表记录了每个闪存块写入的 LBA,该 P2L 数据写在该闪存块的某个位置(或单独存储)。当回收该闪存块时,首先把该 P2L 表加载上来,然后根据上面的 LBA,依次查找映射表,决定该数据是否有效,有效的数据会被读出来,然后重新写人。采用该方法,不需要把该闪存块上的所有数据一股脑地读出来,但还是需要查找映射表以决定数据是否有效。因此,该方法在性能上介于前面两种方法之间,在资源和固件开销上也是处于中间的。
实际上就是将闪存单元中的逻辑地址信息提取出来放到一张表中,节省的是读取闪存块的时间。
3. 把有效数据写入到目标闪存块
当有效数据读出来时,最后一步就是重写,即把读出来的有效数据写入闪存。
4. 垃圾回收时机
- 可用闪存块小于一定阈值,就要进行
Foreground GC(前台垃圾回收),这是被动的方式 - 与之相对应的
Background GC(后台垃圾回收),是在 SSD Idle(空闲)的时候主动进行 GC
四、Trim
对一个文件 File A 来说,用户看到的是文件,操作系统把文件划分为若干个逻辑块,然后写入 SSD 的闪存空间。当用户删除掉文件 File A 时,其实它只是切断用户与操作系统的联系,即用户访问不到这些地址空间;而在 SSD 内部,逻辑页与物理页的映射关系还在,文件数据在闪存当中也是有效的。
Trim 是一个新增的 ATA 命令(Data Set Management),专为 SSD 设计。当用户删除一个数据时,操作系统会发 Trim 命令给 SSD,告诉 SSD 该文件对应的数据已经无效。
SCSI 里面的同等命令叫 UNMAP,NVMe 里面叫 Deallocate,它们指的都是同一个功能。
SSD 收到 Trim 命令时,固件要按顺序做以下几件事:
- 清除 L2P table 到空地址
- 清除 Valid Page Bit map(VPBM) 上对应的 bit
- 更新 Valid Page Count(VPC)
- 重复以上 3 步直到完成每一个 LBA
- 根据新的 VPC 重新计算 GC 的优先级
- 回收最少 VPC 的 block
- 擦除全是垃圾的 block
步骤 5~7 是 Trim 命令处理后,GC 的处理,它们不是 Trim 命令要处理的事情,Trim 命令是不会触发 GC 的。
五、磨损平衡
磨损平衡,就是让 SSD 中的每个闪存块的磨损(擦除)都保持均衡。
在这之前,我们先抛出几个概念: 冷数据(Cold Data)和热数据(Hot Data),年老的(Old)块和年轻的(Young)块。
所谓冷数据,就是用户不经常更新的数据,比如用户写入 SSD 的操作系统数据、只读文件数据、小电影等;相反,热数据就是用户更新频繁的数据。数据的频繁更新,会在 SSD 内部产生很多垃圾数据(新的数据写入导致老数据失效)。
所谓年老的块,就是擦写次数比较多的闪存块;擦写次数比较少的闪存块,年纪相对小,我们叫它年轻的块。SSD 很容易区分年老的块和年轻的块,看它们的 EC(Erase Count,擦除次数)就可以了,大的就是老的,小的就是年轻的。
动态磨损平衡(Dynamic WL):将热数据写到年轻的块上
静态磨损平衡(Static WL):将冷数据写到年老的块上
动态磨损均衡和静态磨损均衡可能导致冷数据和热数据放到同一个闪存块上,冷数据、用户刚写入的数据和 GC 数据可能混在一起。这样在 GC 的时候冷数据可能就会被经常移动,增大了写放大。
解决的策略:做静态磨损均衡的时候,用专门的闪存块来存放冷数据,不与用户或者 GC 写入同一个闪存块
六、掉电恢复
掉电分为两种:正常掉电和异常掉电。
正常掉电
掉电前,主机通过命令通知 SSD,收到命令之后,会做以下几件事:
- 把 buffer 中缓存的用户数据刷入闪存
- 把映射表刷入闪存
- 把闪存的块信息写入闪存(比如当前写的是哪个闪存块,以及写到该闪存块的哪个位置,哪些闪存块已经写过,哪些闪存块又是无效的等)
- 把 SSD 其他信息写入闪存
正常掉电不会导致数据的丢失,重新上电之后 SSD 只需将上述信息重新加载即可。
异常掉电
SSD 中不只有闪存,还有用来存储映射表等用户数据的缓存,这用的是 RAM(DRAM 或 SRAM)。
一个办法是将 SSD 加上电容,当检测到异常掉电时,电容放电,将 RAM 中的数据刷到闪存中,这样的 SSD 需要有异常掉电处理模块。
还有一种前卫的想法,就是用一种掉电不会丢失数据的材料来代替 RAM,例如 3D XPoint.
SSD 的异常掉电恢复主要是映射表的恢复,SSD 在把用户数据写到闪存的时候,会额外打包一些数据,我们叫它元数据(Meta Data),它记录着该笔用户数据的相关信息,比如该笔数据对应的逻辑地址、数据写入时间(时间戳)等,如下图:
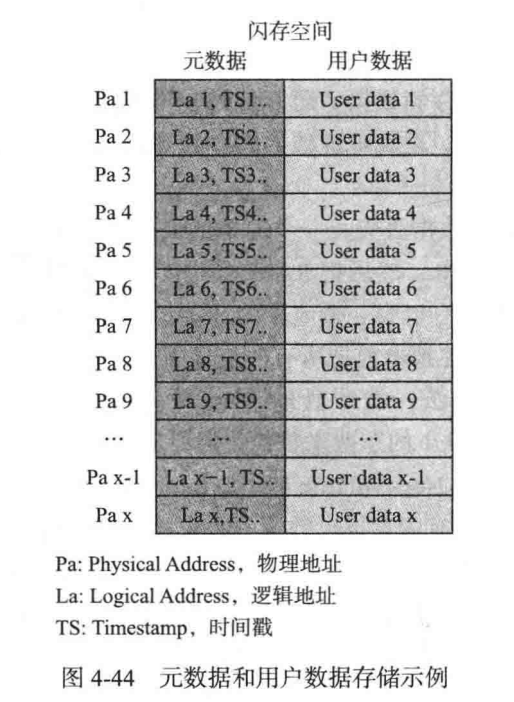
以图 4-44 为例,如果我们读取物理地址 Pa x,就能读取到元数据 x 和用户数据 x,而元数据是有逻辑地址 La x 的,因此,我们就能获得映射: La x→Pa x。映射表的恢复原理其实很简单,只要全盘扫描整个闪存空间,就能获得所有的映射关系,最终完成整个映射表的重构。
若同时存在新老数据,那么便会根据时间戳来获得最新的数据,从而构建映射。但是如果 SSD 容量很大的话,这样的全盘检查耗时会很久,其中一种办法就是 SSD 定期把 SSD RAM 中的数据(包括映射表和用户缓存的数据)和 SSD 相关的状态信息(诸如闪存块擦写次数、闪存块读次数、闪存块其他信息等)写到闪存中去,这个操作被称为 Checkpoint(检查点),或 “快照”,这样掉电后只需要扫描局部的物理空间,节省了大量时间。
七、坏块管理
来源: 一般来自于出厂自带的坏块和使用中产生的。
坏块鉴别
- 它会在出厂坏块的第一个闪存页和最后一个闪存页的数据区第一个字节和 Spare 区第一个字节写上一个非 OxFF 的值
- 一部分厂商会将坏块的信息表存储在闪存中
坏块管理
- 略过(Skip)
- 用户写闪存的时候,一遇到坏块就越过,写下一个 Block
- 替换(Replace)
- 当某个 Die 上发现坏块时,会被 Die 上某个好块替换,用户写数据时,不是跳过这个坏块,而是写到替换的好块上
- 整个 Die 空间分为用户空间和预留空间
- 采用替换策略的话,SSD 内部需要维护一张重映射表(Remap Table),即坏块到替换块的映射
两种策略的优劣:
略过策略的性能不稳定,并行度可能在 1~4 个 Die 之间(假设有 4 个 Die),但是替换策略有木桶效应,如果某个 Die 质量较差,整个 SSD 可用的闪存块受限于那个坏的 Die。
八、SLC Cache
SLC 相比 MLC 和 TLC,有更好的性能和寿命,有些 SSD 用其来做 Cache,让 SSD 有更好的突发性能(Brust Performance)。
这里所说的 SLC Cache,不是说单独拿 SLC 闪存来做 Cache,而是把 MLC 或者 TLC 里面的一些闪存块配置成 SLC 模式来访问,而这个特性一般的 MLC 或者 TLC 都是支持的。SLC 模式下的闪存块,相比 MLC 或者 TLC 模式下的闪存块,更快更耐写,可以用来做 Cache。
SLC Cache写入策略有:
- 强制 SLC 写入
- 用户写入数据时,必须先写人到 SLC 闪存块,然后通过 GC 搬到 MLC 或者 TLC 闪存块、
- 能够保护 Lower Page 的数据
- 非强制 SLC 写入
- 用户写人数据时,如果有 SLC 闪存块,则写入到 SLC 闪存块,否则直接写到 MLC 或者 TLC 闪存块
- 具有更好的后期写入性能
SLC Cache 办法:
- 静态 SLC Cache:拿出一些 Block 专门做 SLC Cache
- 动态 SLC Cache:所有的 MLC 和 TLC 都可以用来做 SLC Cache
- 两者混合
九、RD & DR
RD 指的是 Read Disturb,DR 指的是 Data Retention。两者都能导致数据丢失,但原理和固件处理方式都不一样,下面分别介绍。
1. RD
闪存块在读取时需要在其他字线(Wordline)上施加电压,时间一长,电子进入浮栅极过多,从而导致比特翻转(1->0),当出错比特数超过 ECC 纠错能力时,数据便会丢失,这就是 RD。
我们要保证每个闪存块读取的次数低于某个阈值,在比特翻转前就将其刷新,这样可以避免 RD。因此 FTL 应该要记录每个闪存块读取次数的表。当然为了避免“过刷新”的问题,可以在读次数超过阈值后,先检测比特翻转数,若不需要刷新,则可以设置一个更大的阈值。最理想的阈值是根据 SSD 的 PE 数动态设置。
对于刷新动作,也分为阻塞(Block)和非阻塞(Non-Block),一般采用非阻塞。
2. DR
SSD 使用时间长了之后,会有电子逃逸,当逃逸的电子到一定数量的时候,就会使存储单元的比特发生翻转(0->1,注意 RD 是 1->0),解决办法仍然是扫描闪存空间,若检测到比特翻转超出一定阈值,进行刷新。
十、Host Based FTL
按照 FTL 放在哪里进行划分,分为 Host Based FTL 和 Device Based FTL
总体来说,Device Based 存在以下缺点:
- FTL 架构通用,不能针对具体应用做定制化。控制器芯片功能复杂,设计难度大,研发成本高
- 闪存更新很快,一般每年闪存厂商都会推出新一代产品,有新的使用特性,需要控制器芯片做出修改,但是芯片改版成本很高
- 企业级应用需要高性能、大容量,通用控制器芯片支持的最大性能和容量有限制企业级市场需求多种多样,有些需求需要控制器提供特殊功能支持,这些是通用 SSD 主控芯片无法提供的。
百度的欧阳剑团队在国际著名的计算机体系结构学术会议 ASPLOS’14 上发表了一篇文章,介绍他们研发的软件定义闪存 SDF(Software Defined Flash)。相比市场上销售的 SSD,SDF 主要的特点有:
没有垃圾回收。SDF 的使用者使用闪存块大小的整数倍为单位来写数据(比如8 MB),所以每个闪存块里面不会有垃圾,或者整体都是垃圾,写之前整体擦除就可以。这样的好处有:
- SSD 内部不用做垃圾回收,读写带宽得到提高
- 不需要预留空间,释放出 20% 的额外空间
- 没有内部搬移数据产生的写操作,闪存没有了写放大,寿命延长
没有闪存级 RAID。SSD 内部其实是闪存阵列,所以为了数据安全性,很多企业级 SSD 会用闪存组成 RAID 组,用一块或几块闪存保存RAID 数据。但是互联网公司的数据一般都有3个备份,所以不担心 SSD 内部数据丢失,因此,RAID是没有必要的
FPGA 作为控制芯片,功能很少:ECC、坏块管理、地址转换、动态磨损均衡。Virtex-5 FPGA 实现了 PCIe 接口和 DMA,Spartan FPGA 则是闪存控制芯片
SSD 内部每个通道都向用户开放,由用户选择写哪个通道
软件接口层非常简单,相比传统的 Linux 存储堆栈,省略了文件系统、块设备、IO 调度、SATA 协议等,用户可以直接使用 IOCTRL(设备驱动程序中对 IO 设备的通道进行管理的函数)来发同步的写命令到 PCIe 驱动