1025. 反转链表

这个题目第一眼看上去不知道怎么处理链表结点的地址,以及不知道如何用简便的方法将链表反转过来,如果用常规的设置链表的结构体来逆置链表,会比较麻烦。而且输入的结点并不是按照链表顺序给出的,并且地址是人为设定的,因此用结构体的方法会非常麻烦,因此考虑用数组来存储链表相关地址信息和顺序关系。
并且,翻转链表可以使用algorithm头文件中的reverse函数,会非常简便。
要注意输入的结点可能是一个完整的链表,他可以从中间断开,此时我们只要找到以头结点开始的那个链表就可以了。
完整代码参考了柳婼的代码:
1 |
|
1035. 插入与归并

分析:先将 i 指向中间序列列中满⾜足从左到右是从⼩小到⼤大顺序的最后⼀一个下标,再将 j 指向从 i+1 开始,第一个不不满⾜足 a[j] == b[j] 的下标,如果 j 顺利利到达了了下标n,说明是插⼊入排序,再下⼀一次的序列列是 sort(a, a+i+2);否则说明是归并排序。归并排序就别考虑中间序列列了了,直接对原来的序列列进⾏行行模拟归并时候的归并过程,i 从0 到 n/k,每次一段段得 sort(a + i * k, a + (i + 1) * k); 最后别忘记还有最后剩余部分的 sort(a + n / k * k, a + n); 这样是一次归并的过程。直到有一次发现a的顺序和b的顺序相同,则再归并一次,然后退出循环
AC代码
1 |
|
1040. 有几个PAT(25) [逻辑题]
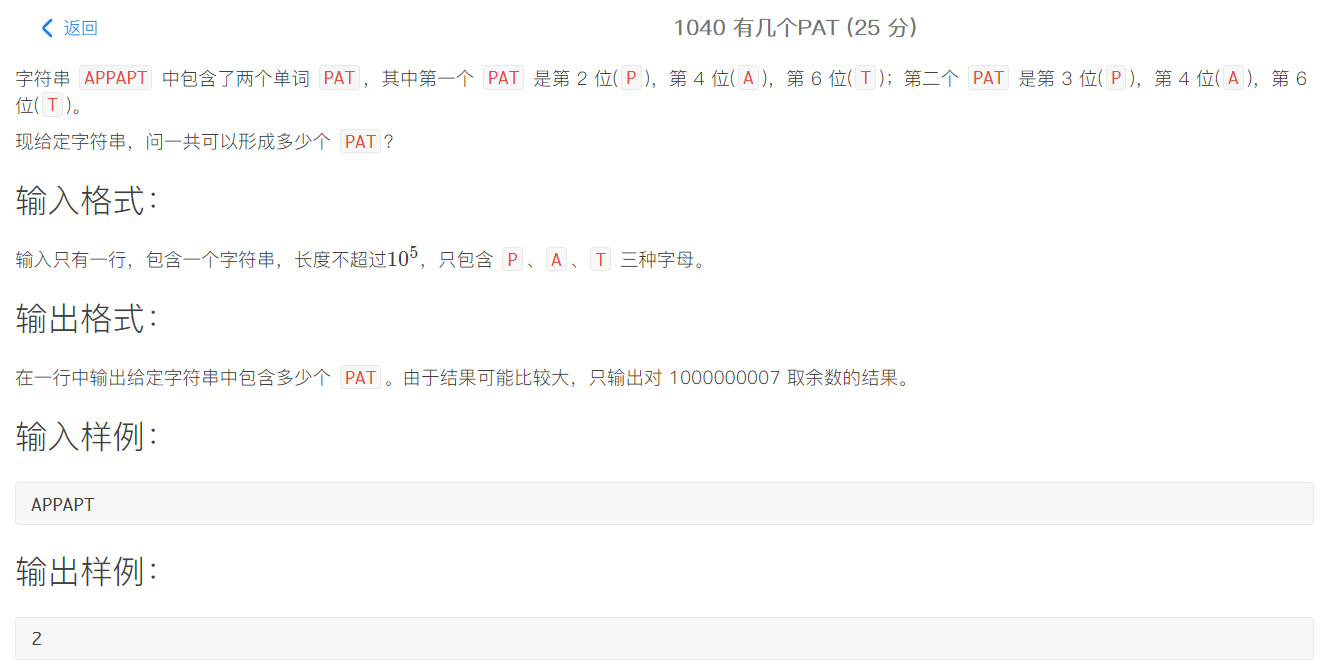
这是一道思维题,要想知道构成多少个PAT,那么遍历字符串串后对于每一A,它前⾯面的P的个数和它后⾯面的T的个数的乘积就是能构成的PAT的个数。然后把对于每一个A的结果相加即可。只需要先遍历字符串串数一数有多少个T,然后每遇到一个T,便countT–-;每遇到一个P呢, countP++;然后一遇到字⺟母A呢就countT * countP,把这个结果累加到result中~~最后输出结果就好啦~~对了了别忘记要对10000000007取余哦~~
穷举遍历显然会超时~~
1 |
|
1045. 快速排序(25)
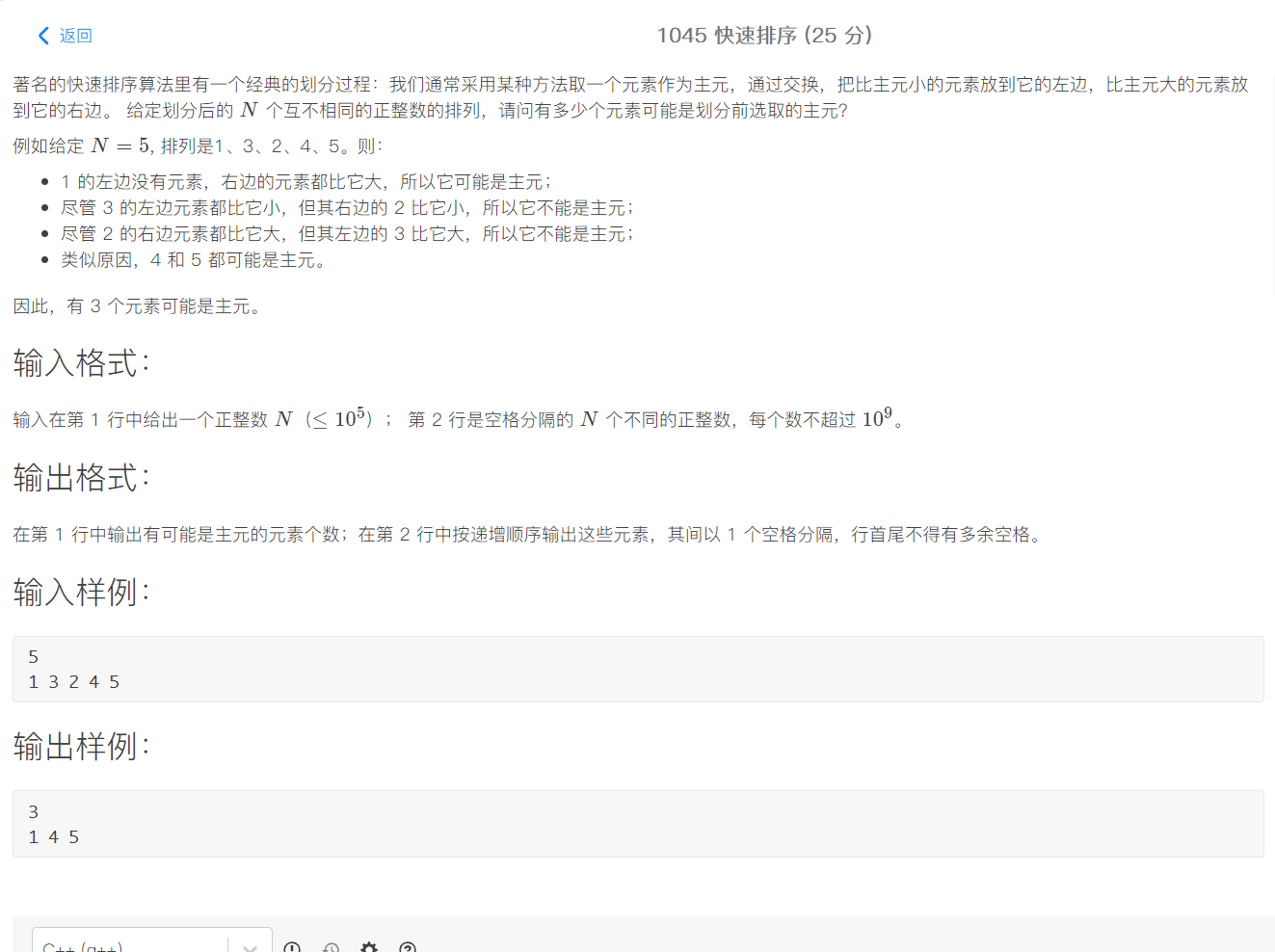
分析:先看数据规模,1e5,如果用穷举,平方之后就是1e10,肯定超时,于是要想其他方法。
对原序列sort排序,逐个比较,当当前元素没有变化并且它左边的所有值的最大值都比它小的时候就可以认为它一定是主元(证明正确性:因为无论如何当前这个数要满足左边都比他大右边都比他小,那它的排名【当前数在序列中处在第几个,也就是相对位置】一定不会变)
一开始测试点 2 段错误,后来才想到如果没有主元存在的话,v[0]非法访问,改正后发现格式错误,然后加了句换行才正确。
AC代码:
1 |
|
1049 数列的片段和 (20)
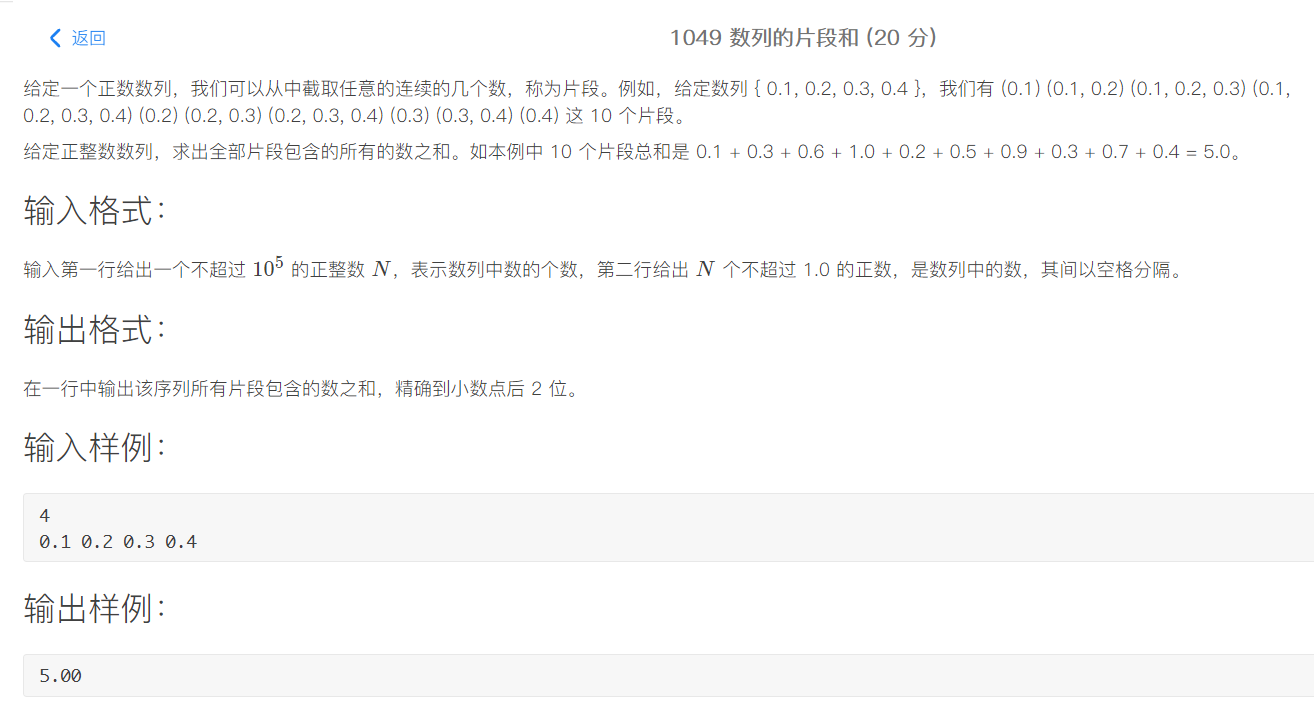
总结 printf() 和 scanf() 函数:如果输入的是 float 型数据,那么用 %f 来接收;如果输入的是 double 型数据,那么用 %lf 来接收;如果输入的是 long double 型数据,那么用 %llf 来接收。
但后来这道题的测试点 2 数据进行了更精细地改动,大概是将 N 改为 10 的 5 次方,此时会用 double 类型数据进行大量的计算,而由于数组中的每个数都小于 1.0,因此很有可能出现 double 小数精度不够用的情况而导致精度丢失,这时候计算出来的结果有可能会有偏差了。
查阅资料后得出以下两种方法:
- 对每个输入的数据都先乘1000(只能乘以1000,可能乘多了就会导致整数部分精度丢失了,可以把这个结果想象成 63 位的队列,队接近队头部分是整数,接近队尾部分是小数,那么小数位数多了就会从队尾“丢出”丢失了的精度,整数位数多了就会从队头“丢出”丢失了的精度),这样就降低了小数位数,最后再对累加的结果除以之前乘的数字即可。
- 这个方法就更简单了,每当我们用
int型发现范围不够的时候会怎么办?难道会先去把这个数除以 1000,再把最后的结果乘以之前除掉的数字吗?当然不会,一般都是把int类型改成long long类型(为啥不是long类型,而是long long类型呢,这就涉及到另一个需要记忆的内容了:因为long int、long、int这三者都是 4 字节的,一样长,想不到吧?)说了那么多没有用。。。正解就是把total的类型改成long double就行了,这时候total的小数精度范围更大,就能完美解决测试点 2 出现的精度丢失问题。 double类型占8字节,用%lf或%f控制输出,long double一般占 12 字节用%Le %Lf %Lg控制输出
1 |
|
1095 解码PAT准考证 (25)
纯模拟题,细心即可
[注]:ios::sync_with_stdio(0);可以加速 cin 和 cout 的输入输出速度,还有 cin.tie(0);。
1 |
|
1099 性感素数 (20)
这题的主要问题是当给定的数不是 Sexy Prime 时,要找比他大的最小符合条件的数,可以与比他小 6 的组成一对,并不一定是比他大 6 的数组成一对。
1 |
|
1100 校庆 (20)
这题问题还是超时,用 map 进行查找可以将数量级压缩在 O(n).
1104 天长地久 (20)
这题主要就是要注意超时问题,可以推出来末尾一定是 99(我感觉题目“天长地久”已经有暗示了),然后在末尾 99 的基础上每次加 100 就行了,这样循环数量级变成 1e7,就不会超时了。