自旋锁
该篇博客参考了《多处理器编程的艺术》第七章——自旋锁与争用,相关代码可在 GitHub 仓库 中查看。
一、前置知识
关于自旋锁的内容,需要有以下几个方面的基础知识:基本数据结构(链表,队列)、操作系统中进程调度、锁及死锁、计算机体系结构中 cache 一致性、计算机组成原理中 cache 结构、Java 基本语法及 concurrent 包的基本用法。
二、背景介绍
在如今多线程环境下对于共享临界资源的访问,需要加锁实现互斥。拿到锁的线程获得 CPU 执行临界区代码,而未拿到锁的线程通常来说有两种处理方式,一种是该线程进入循环等待,直到它等待的那个 CPU 空闲,然后获得 CPU 开始执行;另一种便是将自己阻塞,等待操作系统重新调度。
前一种锁叫 自旋锁,后一种锁叫 互斥锁。
先举一个很容易理解的例子。有两个进程,分别为 P1 和 P2,这两个线程做的工作都是将变量 a 加 1,就像这样:
1 | int a = 0; |
如果执行这两个线程各 100 次,我们预期的结果是 a = 200,但是实际上结果并不是我们想象的这样,它有可能是 200,但是更多的情况是一个小于 200 的数。
在计算机底层上,对一个数执行加一操作,编译器会将其编译成下面三条指令:
1 | mov ax, mem |
当多线程执行时,代码执行顺序将不可控,因此会出现一个线程还未将值写进内存的时候,其他线程就读取内存中的值,造成数据相关问题。
三、TAS 锁与 TTAS 锁
3.1 TAS 锁
TAS(testAndSet) 是一个原子操作,它的功能是将 true 原子地写入变量,然后获取变量之前的值,即用 true 来交换变量的值。
为什么这个操作是原子的呢?因为在 x86 汇编中有个指令叫 xchg,它的功能便是交换两个数。
在 Java 中,有个与其功能一致的函数叫 getAndSet(),下面是 TASLock 的实现。
1 | public class TASLock { |
这里的 AtomicBoolean 是原子布尔类型,能够实现原子的赋值,来自 java.util.concurrent.atomic.AtomicBoolean。
这个锁通过代码很容易理解:当线程 A 获取锁时,将 state 置为 true,若线程 A 还未释放锁时,其他线程 B 若也要申请锁,便会在 while (state.getAndSet(true)) {} 空转,直到 state 为 false,然后线程 B 便可以申请到锁了。
我们先来看一下另一种形式的 TAS 锁,然后将两者进行比较。
3.2 TTAS 锁
直接看具体实现。
1 | public class TTASLock { |
TTAS 锁并没有每次都直接调用 getAndSet(boolean) 方法,而是先判断 state 变量是否为 true,若为 true 便无需用 true 和原先的值进行交换。而若 state 变量是 false,则再对 state 执行 getAndSet。
因为这里有两次 test,因此该锁叫 TTAS(testTestAndSet) 锁。
当然从加锁的正确性来说,这两种锁是等价的,都可以保证无死锁的互斥,对于简单的情况,这两种并无明显差别。但是在多处理器上运行大量线程,这两种锁将会展现出指数级别的效率差距。
下面是 n 个线程分别执行一段临界区代码所需的时间图,在没有任何争用干扰的情况下,最下面的平直曲线应该是理想情况(实际上并不可能)。可以看出这三条曲线差距非常明显。
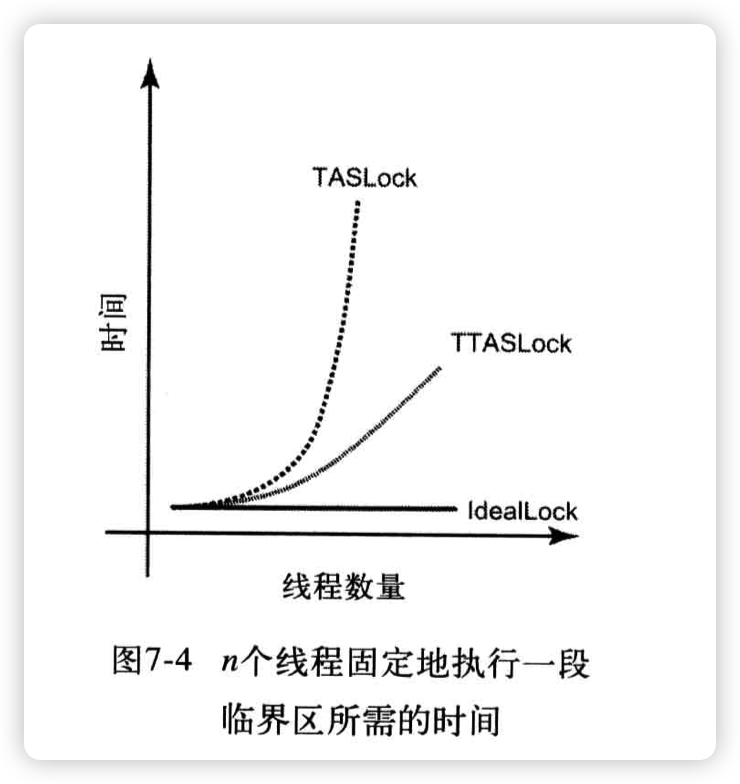
上图的情况可以用多处理器的系统结构进行解释。
3.3 比较两种锁的性能差距
首先我们要确定的是,现代处理器几乎都包含高速缓存(cache),cache 与内存的一致性问题是现代处理器研究的重要问题;CPU 访问内存的时间时间比访问 cache 的时间多 2~3 个数量级。
多处理器中的 cache 一致性问题这里不展开讲述,大致内容如下。
每个处理器都有一个自己的 cache,考虑以下情况:处理器 A 访问数据 x(假设 x = a),将 x 放入 cache_A 中,处理器 B 也想访问 x,而 cache_B 中没有对 x 的缓存,这个时候处理器 B 便会在 cache_A 中查找 x,找到之后将其放入自己的缓存中(此时 x = a)。这时处理器 A 修改了 x 的值(假设修改为 b),并更新自己的 cache,若此时处理器 B 再次访问 x,它首先会从自己的 cache 中找,而目前 cache_B 中存放了 x = a,但是目前最新的值是 x = b,产生了错误,这就是 cache 一致性问题。
解决 cache 一致性问题的一个解决办法便是在一个处理器更新自己的 cache 后,该处理器在总线上广播这个地址,其他处理器监听总线,如果其他处理器在自己的 cache 中发现了同样的地址,则将对应的 cache 置为无效。
然后我们再来分析 TAS 锁。
在 TAS 锁中,每个线程每次执行都将调用 getAndSet 方法,而这个方法需要写入变量,因此在修改变量前需要在总线上进行广播,通知其他处理器将该 cache 行置为无效。而这便会带来两种问题:一是广播占用了总线流量,当的确需要从内存中读取值时便会造成总线上的延迟;二是每次修改变量是会造成其他处理器的 cache 缺失,即其他自旋的线程每次都会遇到 cache 不命中的情况,便需要通过总线获取新的值。同时,当持有锁的线程尝试释放锁时,因为总线拥挤而不得不被迫延迟,这样的多米诺骨牌效应只会导致效率越来越低。
总结来说,TAS 锁存在着大量的总线占用,每个线程每一次自旋都会产生大量的总线流量,从而使得其他线程也必须延迟,最终造成了系统的效率急剧降低。
而 TTAS 锁中,当线程 A 持有锁时,线程 B 第一次读锁时会发生 cache 缺失,但是只要线程 A 持有锁,线程 B 便只要不断读取值,这样每次 cache 都将命中,不产生总线流量,也不会影响其他线程对总线的使用。
当然当持有锁的线程释放锁时,会导致所有正在自旋的线程的 cache 失效,从而导致大量总线流量,但是短暂过后所有线程将归于平静,又将回到本地自旋的状态。
四、指数后退锁
我们现在考虑如何改进 TTAS 锁的算法,这里先引出一个术语:争用,争用的意思是多个线程试图同时获得一个锁。在上面的 TTAS 锁中,在两个 while 循环之间可能会产生高争用现象,此时线程获得锁的几率非常小,并且还会带来极高的总线流量。我们可以考虑将某些线程推迟一段时间再去尝试获得锁,这样同时申请锁的线程将减少,实际证明这样的效果行之有效。
那么应该将线程退后多长时间呢?了解过计算机网络中 CSMA/CD(载波监听多路访问/碰撞检测)中的二进制指数退避应该很容易想到,这里的指数后退与其相似。线程随机在 (0, limit) 中后退一段时间,若还未获得锁,那么将 limit 加倍,再次重新在 (0, limit) 获取一个随机值进行后退,直到 limit 到达一个设定的最大值 maxDelay。下面是代码实现。
Backoff.java:
1 | public class Backoff { |
BackoffLock.java:
1 | public class BackoffLock { |
对于 BackoffLock 的性能,与 minDelay 和 maxDelay 的值的选取密切相关,要根据实际任务及自身处理器及架构的情况合理设置阈值。
五、队列锁
5.0 队列锁的介绍
队列锁是一种易于扩展的自旋锁,尽管稍微复杂一点 (亿点),但是具有更好的移植性。
在指数后退锁中,存在两个问题。
- 一是所有线程获得锁都依赖于同一个变量
state,因此每个线程都在同一个共享存储单元上自旋,每一次成功的锁访问都会带来 cache 一致性流量(尽管相比之下比 TASLock 低); - 二是临界区利用率低,因为很多线程被“后退”了,因此延迟带来的开销是无法忽略的。
可以将这些线程组织成一个链表(队列)来解决这些问题,在队列中,每个线程只要检测前一个线程是否已经完成来判断自己能否成功获取锁,这样每个线程就在不同存储单元上自旋了,也不会有延迟带来的开销。
下面介绍三种队列锁,基于数组的队列锁,CLH 队列锁和 MCS 队列锁。
5.1 基于数组的队列锁
基于数组的队列锁 ALock,其有一个 tail 字段,初始值为 0,它被所有的线程共享,用来表示数组的下标。每个线程原子地增加 tail 字段的值,每个线程还有一个局部变量用来保存这个当前的 tail 值,称为 slot(槽)。如果 flag[j] 为 true,那么表示下标为 j 的线程有权获得锁。
初始状态时,flag 数组只有下标为 0 的那个值为 true,其他均为 false。其他线程调用 lock() 方法尝试获得锁时,会不断地在 flag[slot] 上旋转,直到 flag[slot] == true。在释放锁时,线程将对应于它自己的槽点 flag 设为 false,然后将下一个槽的 slot 设为 true。上述所有操作都要对 n 取模,n 的大小至少为最大的并发线程数。
下面用具体例子来说明基于数组的队列锁。
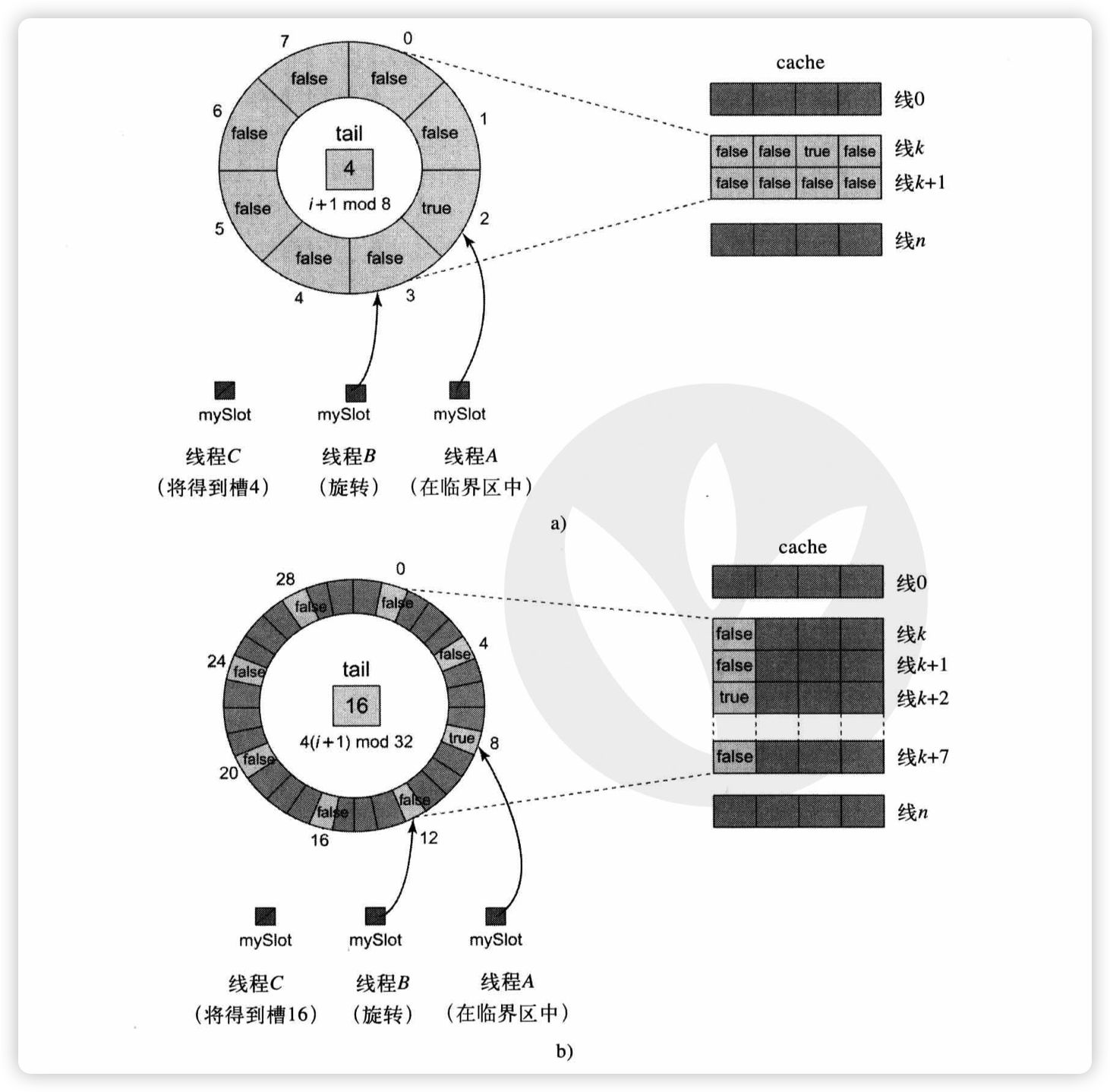
上图的 a) 中,当前获得锁的线程是 A,flag[2] == true,线程 B 和 C 也尝试获得锁,线程 B 和 C 在 flag[3] 和 flag[4] 上自旋等待。当线程 A 释放锁后,flag[2] 设置为 false,flag[3] 设置为 true,线程 B 获得锁。
ALock.java:
1 | import java.util.concurrent.atomic.AtomicInteger; |
在基于数组的队列锁中,mySlotIndex 是线程的局部变量,局部变量不需要与其他线程共享,不需要同步,也就不会产生一致性流量,因为它只能被一个线程访问。尽管 flag 数组是被多个线程共享的,但是在任意特定的时刻,线程对应的 flag 存储单元会被存放在对应的 cache 中,线程是在本地 cache 中旋转,大大降低了无效流量,从而使得对数组的存储单元的争用大大降低。
但是值得注意的是,争用仍然可能发生,因为存在一种“假共享”现象,当相邻的数组元素在同一个 cache 行时,就会发生这样的现象。继续看上面的图 a),假设一个 cache 行能够存放 4 个数组元素,那么 flag[0] ~ flag[3] 都将存放在同一个 cache 行中。当某一个线程对 cache 行执行写操作时,会导致当前 cache 行无效,从而导致其他在该 cache 旋转的线程产生无效流量。
一种解决办法就是上图中的 b),于是我们将数组进行填,充让一个 cache 行只存放一个数组元素,具体实现上只需要将 (i + 1) % 8 改成 4 * (i + 1) % 32 即可。
个人想法:尽管
flag是volatile的,但是在释放锁时,无法保证flag[slot] = false;和flag[(slot + 1) % size] = true;这两个步骤之间进程不被调度。如果先将自己的槽设置为false,然后进程被调度,那么数组所有元素都是false,之后加锁的进程永远无法获得锁。因此,应该先将下一个槽设置为true,尽管假设这个时候进程被调度,也会使得下一个进程成功获得锁(书上代码是先将自己的槽设置为false,然后再将下一个槽设置为true,我给出的示例代码将这两行调换了顺序)。
5.2 CLH 队列锁
ALock 是对 BackoffLock 的改进,因为它将⽆效性降到最低并把⼀个线程释放锁和另⼀个 线程获得该锁之间的时间间隔最⼩化。与 TASLock 和 BackoffLock 不同,该算法能够确保⽆饥饿性,同时也保证了先来先服务的公平性。
但是,ALock 并不是空间有效的,它限定了并发的最大线程数量 n,需要为每一个锁开一个至少为 n 的数组,因此如果有 L 个锁,则需要至少 O(Ln) 的空间。
下面介绍一种基于链表的锁,CLHlock。锁本身被表示为 QNode 对象的虚拟链表。之所以称之为“虚拟”是因为链表是隐式的,即每个线程通过⼀个线程局部变量 pred 指向其前驱。公共的tail域对于最近加⼊到队列的结点来说是⼀
CLHLock 的数据结构及初始化代码如下所示。
1 | private static class QNode { |
该类在 QNode 对象的布尔型 locked 域中记录了每个线程的状态。如果该域为 true,则相应的线程要么已经获得锁,要么正在等待锁;如果该域为 false,则相应的线程已经释放了锁。
下面是 lock 和 unlock 的具体代码。
1 | public void lock() { |
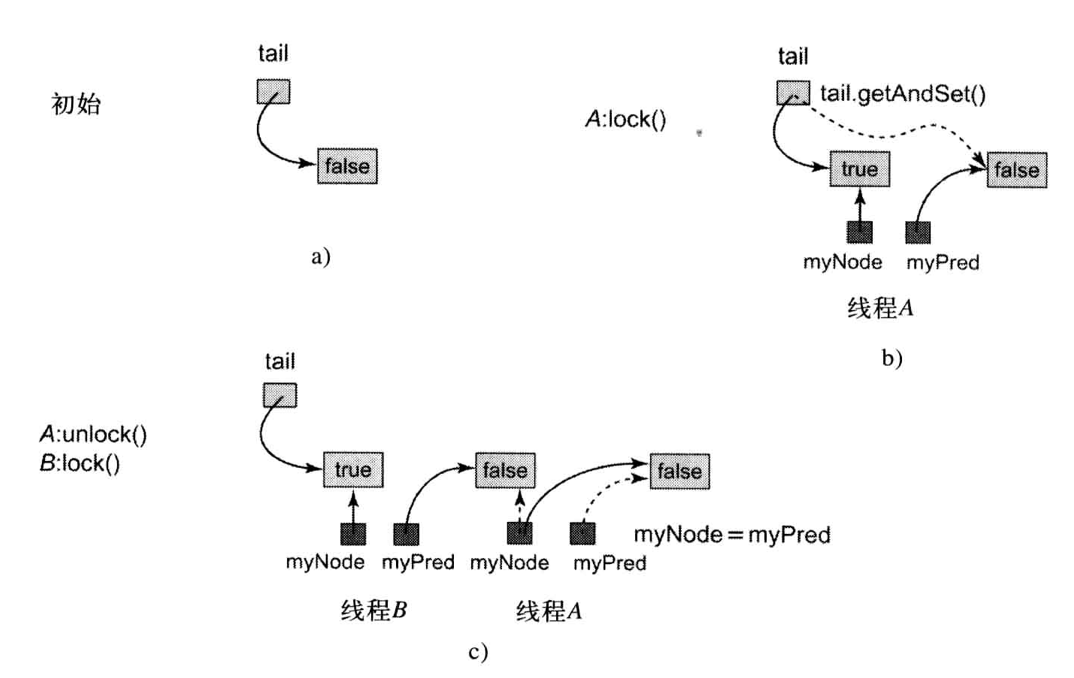
如上图所示,若要获得锁,线程将其 QNode 的 locked 域设true,表示该线程不准备释放锁。随后线程对 tail 域调⽤ getAndSet() ⽅法,使它⾃⼰的结点成为队列的尾部,同时获得⼀个指向其前驱 QNode 的引⽤,最后线程在其前驱的 locked 域上旋转,直到前驱释放该锁。
详细解释一下 CLH 锁的工作原理:tail 为全局变量,在所有线程之间共享,每个线程有两个独立的局部变量,为 myPred 和 myNode,表示当前自己的 QNode 结点和前驱 QNode 结点。
当 A 线程尝试获取锁时,首先获取 myNode 的值,表明当前的 QNode 结点,然后将结点内的 locked 字段设为 true,表明线程 A 不准备释放锁(即想要申请锁),然后取出 tail 的值(此时 tail 记录的是虚拟链表的尾部的 QNode,实际上只是一个变量,并不是链表)赋值给 myPred,表明当前 QNode 的前驱结点,并将当前结点赋值给 tail。在 A 线程获得锁之前,要在 myPred 上空转等待,等待 myPred.locked 为 false 即可获得锁。
当锁申请成功时,tail 存放的结点是当前的 myNode 结点,myPred 是前驱结点,myNode 和 tail 指向的是同一个结点。若要释放锁时,将当前的结点的 locked 字段改为 false,表明释放该锁,然后将当前结点用前驱结点覆盖 myNode.set(myPred.get()),这句话非常重要,这样可以避免同一个线程重复加锁时自旋等待,从而导致死锁。考虑以下情况:在上图中,如果在线程 A 释放锁后,线程 B 获取锁之前,线程 A 再次调用 lock(),那么会直接将线程 A 对应的 QNode 的 locked 字段设置为 true,而这个结点正是线程 B 空转等待的结点(myPred 结点),线程 B 的 myPred 是线程 A 的 myNode,线程 A 的 myPred 是线程 B 的 myNode,互相等待对方释放锁,于是产生了死锁。因此当一个线程释放锁时,需要将自己当前的 myNode 指向其他结点,可以直接指向自己的前驱结点(如上图 c 所示),或者自己再创建一个新的 QNode(可以但没必要)。
由于每个结点释放锁后可以被系统回收,因此 CLHLock 只需要 O(L+n) 的空间。与 ALock ⼀样,该算法让每个线程在不同的存储单元上旋转,这样当⼀个线程释放它的锁时,只能使其后继的 cache ⽆效。该算法⽐ ALock 类所需的空间少,且不需要知道可能使⽤锁的线程的数量。该算法和 ALock 类⼀样,也提供了先来先服务的公平性。
也许这种锁算法的唯⼀缺点就是它在⽆ cache 的 NUMA 系统结构下性能很差。每个线程都⾃旋等待其前驱结点的 locked 域变为 false。如果内存位置较远,那么性能将会受到损失。然⽽,在 cache ⼀致性的系统结构上,该⽅法⾮常有效。
完整的 CLHLock 代码如下。
1 | package spinlocks; |
5.3 MCS 队列锁
MCSLock 也是用 QNode 表示,但是和 CLHLock 不同,它是表示为一个显式链表,通过 QNode 对象中的 next 字段体现,⽽不是由线程的局部变量所体现。
MCSLock 的构造函数和 QNode 对象定义和初始化如下。
1 | private static class QNode { |
下图展现了 MCSLock 的加锁与释放锁的过程。
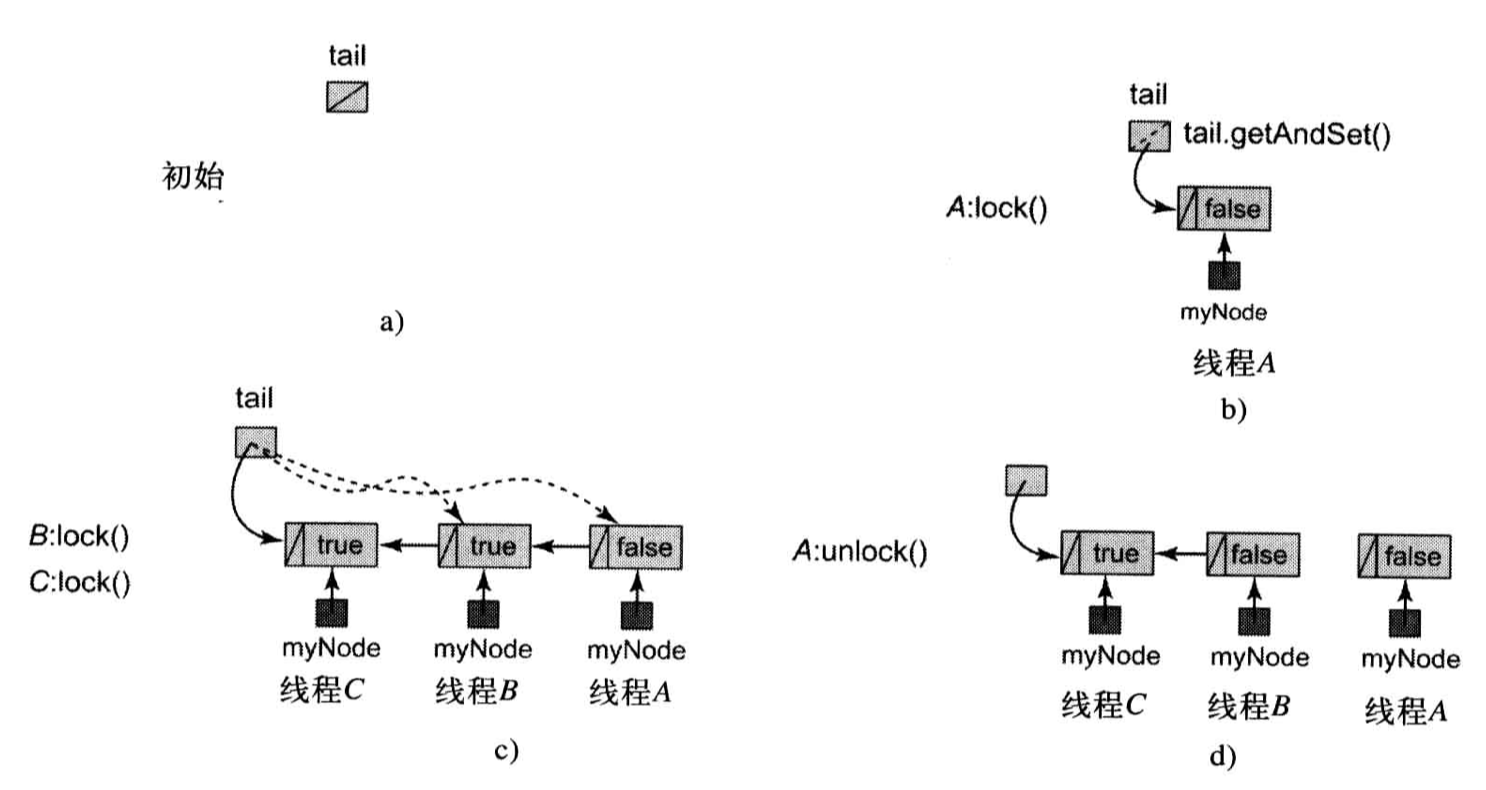
MCSLock 释放锁的过程:检查当前结点是否为链表最后一个结点,如果不是最后一个结点,且 qnode.next 为空,说明下一个结点已经准备申请锁,但是结点的链接还未完成,这时当前线程释放锁需要自旋等待,直到下一个线程将链表链接完成。在任⼀种情形下,⼀旦出现了后继结点,unlock() ⽅法则将它的后继的 locked 域设置 false,表明⽬前锁是空闲的。
最后一句:qnode.next = null 是必要的。若线程释放锁后不将 next 指针置空,则下列这种线程执行情况将导致线程忙等:A.lock() -> B.lock() -> A.unlock() -> A.lock() -> B.unlock() -> A.unlock() -> A.lock(),即当线程队列形成回路时,释放锁时分支 if (qnode.next == null) 将不会进入正确的代码块执行,导致 tail 不会被置为 null,当下一次申请锁进入 lock() 时,就会导致无限空转。
该锁具有 CLHLock 的优点,特别是每个锁释放仅能使其后继的 cache 项⽆效。这种算法更适于⽆ cache 的 NUMA 系统结构,因为是由每个线程来控制它所⾃旋的存储单元的。如同 CLHLock ⼀样,结点能被重复使⽤。因此,该锁的空间复杂度为 O(L+n)。MCSLock 算法的⼀个缺点就是释放锁时也需要旋转,另外⼀个缺点就是它⽐ CLHLock 算法的读、写和 compareAndSet() 调⽤次数多。
完整 MCS 锁代码实现如下。
1 | import java.util.concurrent.atomic.AtomicBoolean; |