l2p cache 优化方案
根据已有的 cache 方案,在 SLC 模式下,由于映射表大小不到 400MB,因此将整个映射表存储在 DRAM 中。
先对这种情况的地址映射进行分析。
1. 映射表和全局映射目录
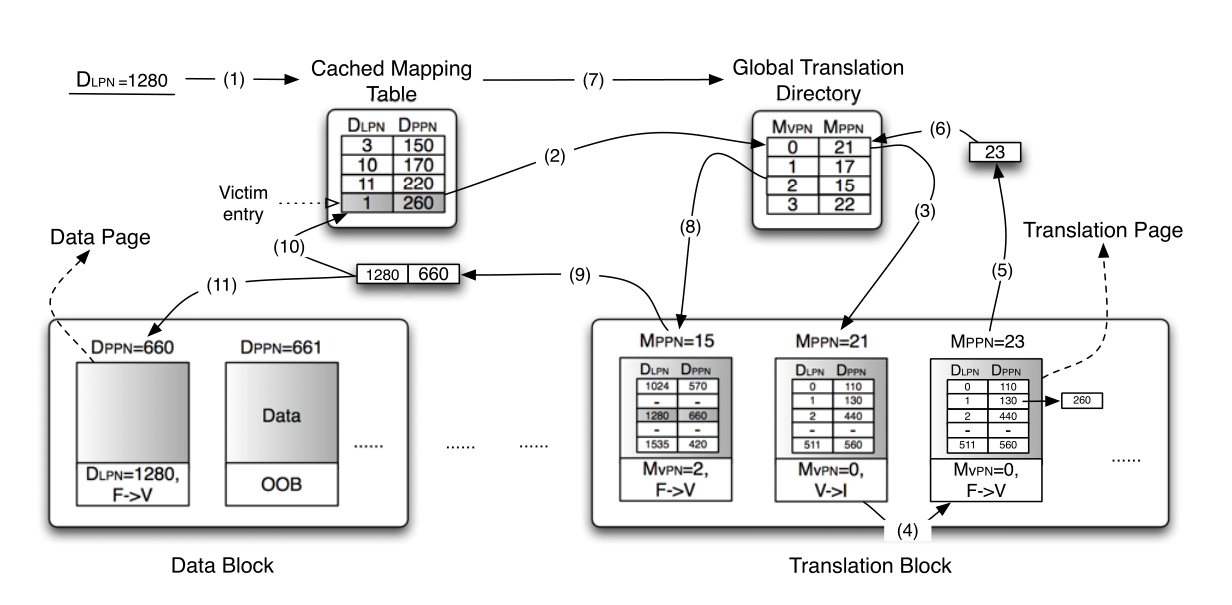
在原先的方案中有两种映射表,一种是存放每一个 page 表项的映射表,每个表项大小为 4B,这个表项用一维数组来存储,数组的下标记录对应表项的逻辑地址。另一种表存放第一种映射表所在 page 的映射,称为 GTD(Global Table Directory,全局表目录),非常类似于二级页表。GTD 表每个表项也是 4B,也用一维数组来表示。数组下标指明逻辑页号的范围,数组元素存放对应的 page 位置。
根据 page 所设定的大小和项目所采用的硬件参数,一个 page 为 16KB,一个表项为 4B,则一个 page 可以存放 16KB/4KB=4K 个表项,GTD 的第一个表项指向存放逻辑地址从 0 到 4K-1 的表项所存储的页的物理地址,GTD 第二个表项则指向存放逻辑地址从 4K 到 8K-1 的表项所存储的页的物理地址。。。以此类推,最后大约需要 7 个 page 即可存储所有 GTD。
2. 物理地址的分配
先对每个逻辑页分配可用的物理页,(首先确保该逻辑地址是有效的,不能重复分配逻辑地址)若该逻辑页被写过,则覆盖对应的物理页。
同时以块为单位,对每个 page 进行管理,用 free, valid, invalid 标记 page 的三种状态
3. cache 优化方案
优化思路为:只将一部分最近使用的映射表以及全部 GTD 放进 DRAM,完整的映射表存放在 flash 中。采用 TPFTL 方案,DRAM 中使用两级 LRU 进行管理。基本思路如下:
缓存中的每个表项根据翻译页进行聚类,即同属于一个翻译页的表项聚合在一个 TP 结点下,TP 结点用一个 LRU 列表进行管理,而每一个 TP 结点下的所有表项也用 LRU 列表进行管理,这样便形成了两级 LRU。
用来管理 TP 结点的 LRU 列表称为页级 LRU,管理每个 TP 结点下表项的 LRU 列表被称为条目级 LRU。每个 TP 结点的热度由该结点下所有表项的平均热度所计算得出,根据这个热度值来决定该 TP 结点在页级 LRU 列表中的位置。
进行 LRU 替换时,先找出页级 LRU 中热度最低的 TP 结点,再从该结点中找出热度最低的表项进行替换,尽管其他 TP 结点中可能有比被替换的热度更低的表项。
另外缓存中还有一个计数器来维护 TP 结点的数量。
DFTL 优化方案
实现步骤:
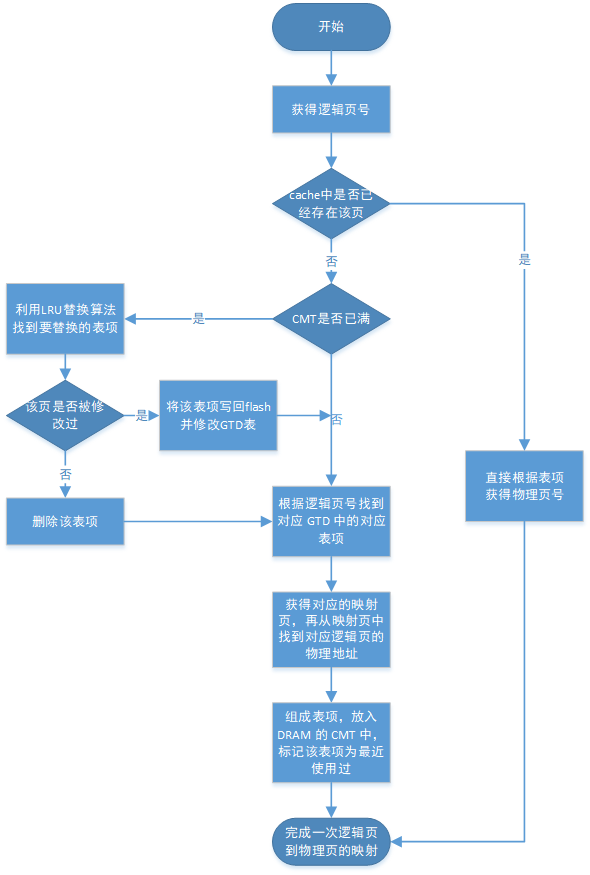
- 首先获得要访问的逻辑页号,检查 cache 中是否已经存在该页
- 若存在,直接访问对应的物理页号,将该表项标记为最近使用过,转到 10
- 若不存在,则进行 4
- 若 CMT(cached mapping table,即 DRAM 存储的部分映射表)中表项没满,转到 6
- 若 CMT 表项已满,则在 CMT 中使用 LRU 替换算法,找到要替换的表项,转到 7
- 根据逻辑页号找到对应 GTD 中的对应表项,然后取出对应的映射页,再从映射页中找到对应逻辑页的物理地址,将其放入 DRAM 的 CMT 中,标记该表项为最近使用过,转到 10
- 检查该页是否被修改过
- 若修改过则将其写回 flash 同时修改 GTD 表,转到 6
- 若没有修改过,删除该表项,转到 6
- 完成一次逻辑页到物理页的转换,重复 1
TPFTL 优化方案
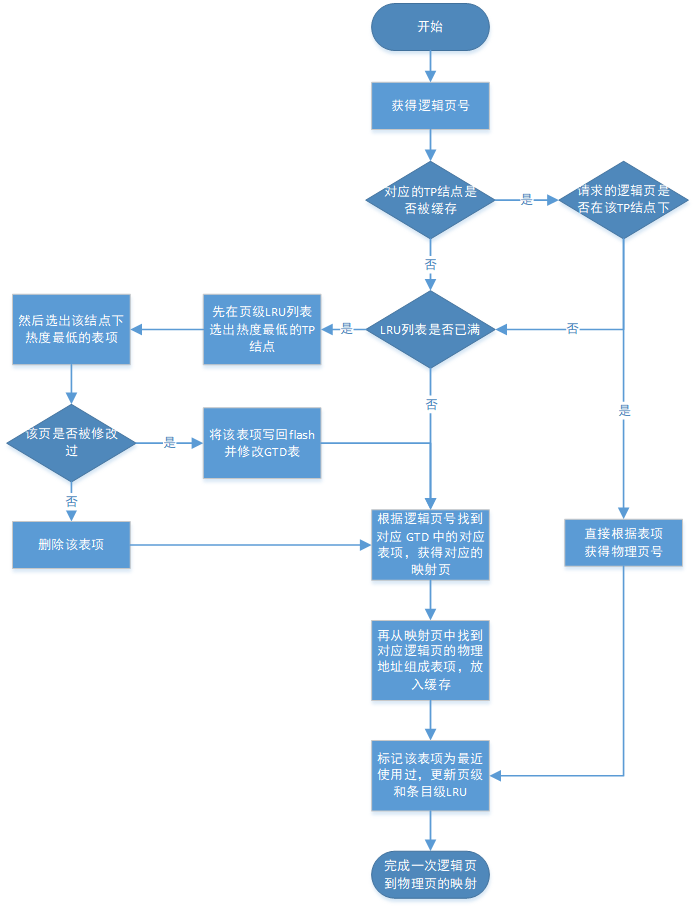
- 首先获得要访问的逻辑页号,根据页号检查对应的 TP 结点是否被缓存
- 若已缓存,检查该结点下的表项,若存在该页,转到 4,若不存在该页,转到 5
- 若没有缓存,则缓存不命中,转到 5
- 访问对应的物理页号,将该表项标记为最近使用过,更新页级 LRU 和条目级 LRU 列表,转到 11
- 若 LRU 列表没满,转到 7
- 若 LRU 列表已满,则先在页级 LRU 列表中选出热度最低的 TP 结点,然后再在 TP 结点下找到热度最低的表项,转到 8
- 根据请求的逻辑页号找到对应 GTD 中的对应表项,然后取出对应的映射页,再从映射页中找到对应逻辑页的物理地址,若 DRAM 中没有缓存该 TP 结点,则创建新 TP 结点,若有 TP 结点而没有表项,则创建新表项,标记该表项为最近使用过,更新页级 LRU 和条目级 LRU 列表,转到 11
- 检查该页是否被修改过
- 若修改过则将其写回 flash 同时修改 GTD 表,转到 7
- 若没有修改过,删除该表项,转到 7
- 完成一次逻辑页到物理页的转换,重复 1
流程图如下所示:
两级 LRU 算法实现思路
1. 时间戳
通过设置一个全局时间戳,在每次替换新表项时,将表项中的流行度字段设置为当前时间戳,每个 TP 结点的平均热度由其下的所有表项的热度的平均值决定。
但是这样会导致两个严重的问题:
- 全局时间戳是一个有范围的整型,系统到一定阶段一定会溢出,这时时间戳就会归零。归零之后表项记录热度所表示的时间戳较小,但是却是最近使用过的;
- 当时间戳较大时(快要到整型所表示的范围时),需要计算 TP 结点的平均热度,这时需要将结点下所有表项的热度相加再取平均,在相加求和的过程中,采用一般的直接相加的方法将会导致溢出。
2. 访问次数
将每个表项的时间戳字段改成访问次数,即根据访问次数来进行替换,先替换访问次数少的,当访问次数相同时,再根据先后次序进行替换。
这样仍然会产生两个问题:
- 只能体现 “最久” 未使用,而不能体现出 “最近”,若一个刚刚被访问的新的表项,访问次数显然为 1,但是它却是刚来的,显然不能被替换;
- 对于两级 LRU,需要计算 TP 结点的平均热度,通过平均访问次数也无法体现出 “最近”,即若一个 TP 结点下频繁发生替换(即命中率不高),那么平均访问次数偏低,但是该 TP 结点却是最近访问的。
3. 命中或替换一个表项时将该表项计数器清零
另一种实现思路是命中或替换一个表项时,将该表项的计数器清零,其余的表项加一,TP 结点下所有表项的计数器平均值越低说明该 TP 结点热度越高。
尽管这样不会出现计数器溢出,但是会导致一个问题:
若命中 TP1 结点下的某一表项,将该表项清零后只将该 TP1 结点的其他表项计数器加一,这样仍然会导致算法不能体现出 “最近”(即频繁访问的 TP 结点由于很多计数器被加了一从而导致该 TP 结点计数器平均值较高)。
提出两种解决方案:
- 在将命中或替换的表项计数器归零时,遍历所有 TP 结点和 TP 结点下的所有表项,将内存中所有表项的计数器全部加一,但是这样可能会导致极大的时间开销(具体的时间开销占比还不清楚,不知道系统是否能容忍这样的时间开销);
- 在 TP 结点上再增加一个字段,用来记录在下一次命中自己之前,其他 TP 结点中命中或替换的次数,等待下次自己被命中时,再将 TP 结点下所有表项的计数器加上该字段值。
最终解决方案
综合考虑后,最终的解决方案在访问次数的基础上进行改进。表项级 LRU 列表以访问的先后顺序进行排序,最新访问的表项插入链表的头部,同时维护一个访问次数字段,TP 结点平均热度就是访问次数的平均值。尽管这样可能会使得最近访问的表项的 TP 结点成为热度最低的结点,但这已经是相对完善且资源消耗较少的方案。每个表项的热度被页面级热度所掩盖,这导致利用时间局部性的效率较低。由于缓存空间利用率的提高,缓存命中率略有提高。
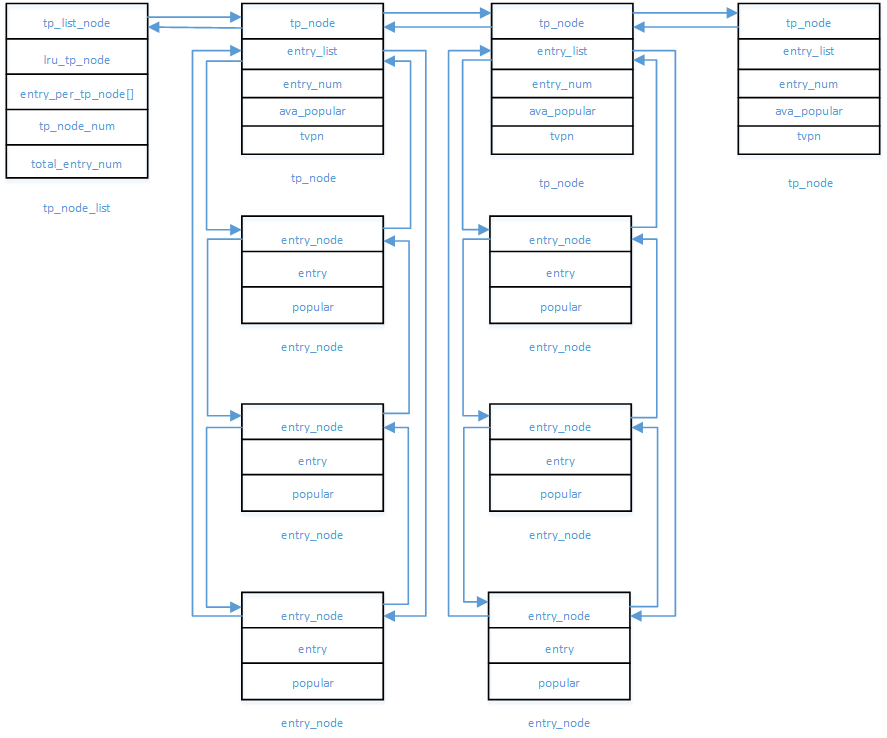
4. 结构体定义
在原来 l2p 模块基础上新增以下结构体。
1 | /** |
下面是结构体之间的关系图。
5. 函数定义
在原有 l2p 模块中函数基础上,新增以下函数。
1 | /** |
原来模块中的函数定义如下。
1 | /* 设置当前 l2p 表项无效 */ |
6. 全局变量
在原有 l2p 模块中全局变量的基础上,新增以下全局变量。
1 | tp_node_list *tp_list; // 管理所有 tp 结点的链表头结点 |
原有的全局变量如下。
1 | psa_entry global_psa; // 记录下一个待分配地址 |
疑问
- psa 地址更新的优先级为什么是
subpage->plane->ch->ce->lun->block->page? - 代码中有两处疑问:
-
l2p.hLine: 42(lun: 1?) -
l2p.hLine: 48(slc_ppa?)
-
- 为什么要记录下一个即将分配的 subpage 物理地址,记录当前的是否能够起到同样的逻辑?
-
u8 free[PAGE_PER_BLOCK / 8 + 1][PAGE_SIZE / SUB_PAGE_SZ];除以 8 是什么意思?(l2p.hLine: 75)
附
- psa:physical subpage address,物理子页地址
- GTD:global table directory,全局表目录
- CMT:cached mapping table,缓存的映射表,存放在 DRAM 中
- TP:translation page
一些问题
是否要进行指令缓存,有竞争情况,是否加锁
DFTL 要改成 TPFTL
更新页级 LRU 和条目级 LRU 列表算法
192MB DRAM
给定 TP 结点数量?TP 结点和 entry 结点总和为 8M 个
读写 flash 步骤:先 FCL_get_free_SQ_entry(u32 ch),返回得到 SQ index,ch 是约定的 flash 中 l2p 表地址的 channel,然后 FCL_set_SQ_entry,最后 FCL_send_SQ_entry
申请一个空的 SQ_entry 之后,如何将参数写入 SQ_entry?
void FCL_set_SQ_entry(u32 hcmd_entry_index, u32 SQ_entry_index, u32 buffer_index, u32 opcode, phy_page_addr *ppa, u32 cmd_sp)里的参数含义,怎么使用?(hcmd_entry_index、cmd_sp 为 0 即可,buffer_index 是内存中你要读写的地址,phy_page_addr 是你要写入的 flash 的地址,全部自己指定)若读取 flash 中的数据,send SQ_entry 之后,通过哪些接口取得该数据?
block_entry *block_table; 用来记录 block 中 page 的状态,指向一个 4 维数组的首地址,访问数组元素的形式可为
block_table[ch][ce][lun][plane](应该是block_table[ch][ce][lun][plane][block]?)重新定义了结构体,TP 结点和 entry 结点数量总和为 8M,每个 tp 结点或 entry 结点结构体大小为 20B,总大小约为 160MB,可映射约 8MB * 4KB = 32GB 的闪存空间。加上结点的状态位 8MB,一共占用空间约为 168MB
block_table记录的是闪存块中每个页的状态,该数据从何处读取g_table和l2p表在闪存中有固定的位置,该位置由谁指定?LRU 实现策略